
北航提出代码大模型的 Scaling Laws:编程语言差异与多语言最优配比策略
北航提出代码大模型的 Scaling Laws:编程语言差异与多语言最优配比策略在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。
来自主题: AI技术研报
7922 点击 2025-12-25 09:46
 搜索
搜索
在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。
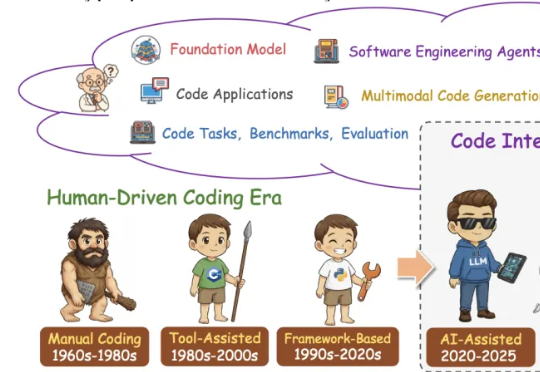
这篇学术论长文由北京航空航天大学复杂关键软件环境全国重点实验室领衔。《From Code Foundation Models to Agents and Applications》一文是对过去几年代码智能领域的一次系统梳理:模型、任务、训练、智能体、安全与应用都被串联成了一条完整、连贯的技术链路。

这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。